
La création d’un répertoire d’archive interrogeable, avec la possibilité de reconstituer les liens qui existent entre les acteurs (personnes, institutions) des documents en question, peut s’avérer, dans le cas de fonds d’archives conséquents, être un outil qui permet au chercheur d’accéder à une vision globale et facilement exploitable de son corpus.
Un “super-répertoire” pour des fonds volumineux
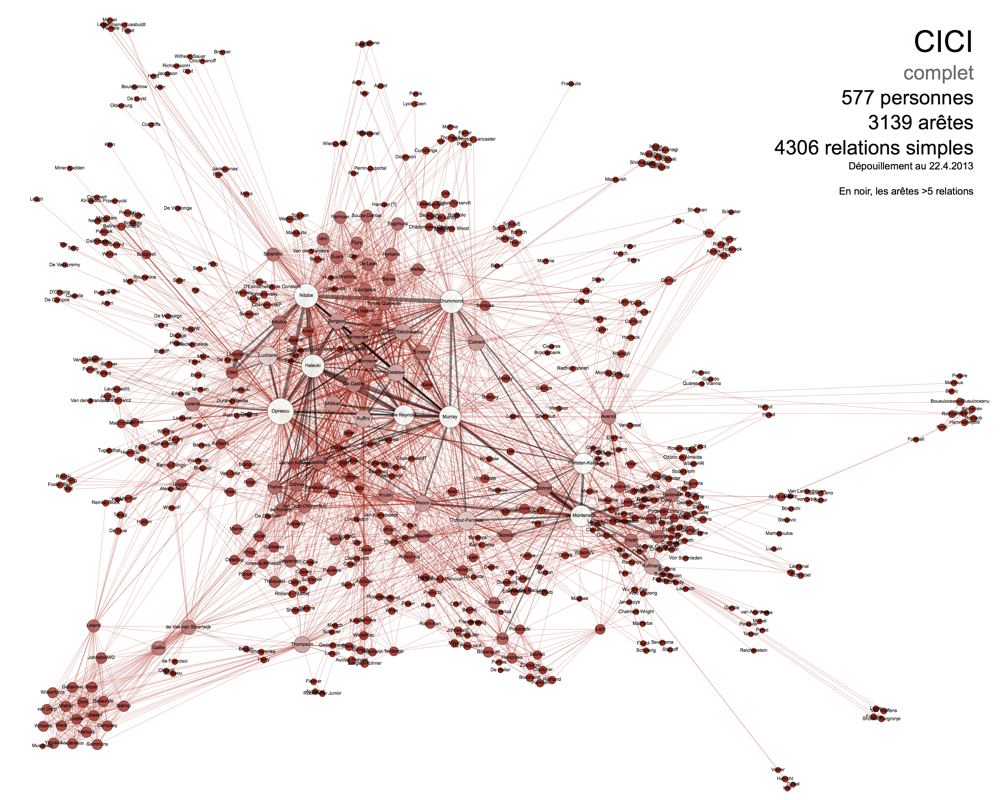
Réseau des relations entre acteurs (expéditeurs/destinataires) des documents contenus dans le fonds de la CICI (dépouillement encore incomplet). 1 sommet = 1 personne / 1 arête = apparition comme acteur du même document.
Dans le cadre de mes recherches sur la Commission Internationale de Coopération Intellectuelle de la Société des Nations, dont le fonds genevois contient un volume très important de cartons d’archives (exemples de documents remarquables : portfolio 1 / portfolio 2), il s’agit de redonner aux milliers de documents une certaine cohérence dans un panorama qui rende ensuite l’exploitation des données efficace. On s’intéresse ici à recenser tous les « acteurs » des documents inventoriés, en particulier les expéditeurs et destinataires de correspondances, pour recomposer le complexe tissu d’échanges d’informations à l’intérieur de l’institution. Augmenté de données prosopographiques, ce procédé rend les recoupements plus aisés, permettant par exemple d’éclairer les affinités entre scientifiques membres des mêmes sous-commissions grâce à des paramètres comme leurs universités d’origine ou le nombre de leurs propres connexions dans d’autres réseaux internes.
Nouvelle perspective : un panorama pour poser ensuite ses questions de recherche
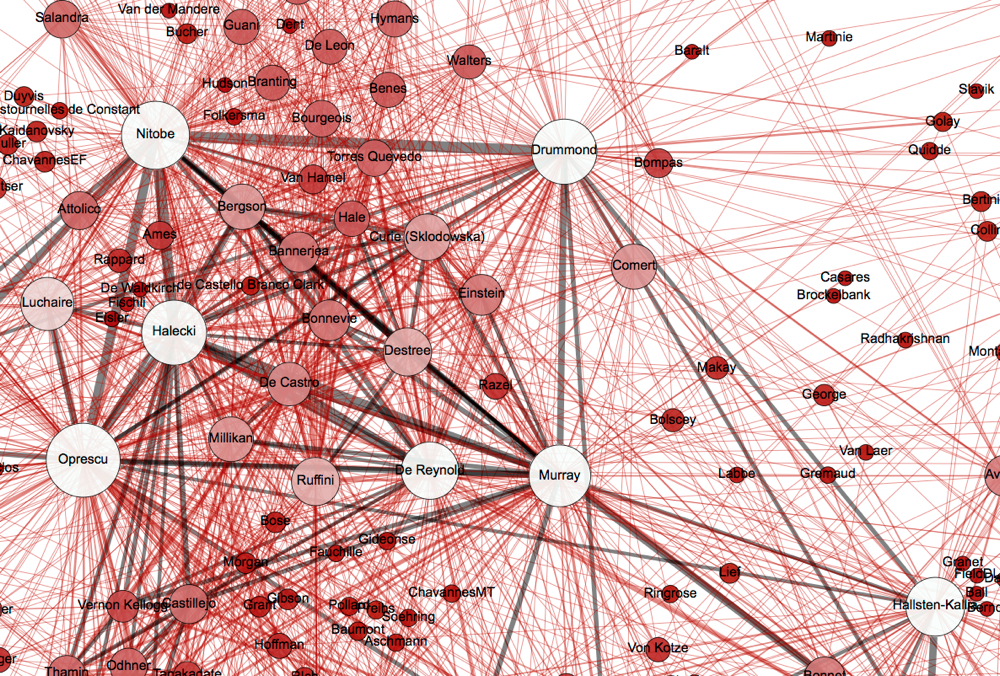
Détail du réseau ci-dessus. On met en évidence en noir les arêtes de valeur égale ou supérieure à 5 (personnes intervenant dans 5 ou plus documents en commun).
Le grand intérêt de dépouiller un fonds en tenant à jour une telle base de données et en la couplant à une analyse du réseau des acteurs des documents réside dans le changement radical de perspective méthodologique que ces opérations impliquent. On assiste en effet à une inversion du cheminement intellectuel : face à un fonds peu exploité et de grande envergure, il ne s’agit plus de le questionner a priori mais de le contempler dans son ensemble, une situation propice à faire naître les questionnements et expliciter les dynamiques, renseignant de plus le processus exploratoire du chercheur face à ses sources et recomposant petit à petit le principe de classement des documents. Face à de telles visualisation, il est primordial de garder à l’esprit que nous ne sommes pas en train de modéliser le réseau des personnes elles-mêmes mais uniquement le réseau des interactions décrites par des documents, témoignage évidemment partiel d’une réalité de l’époque. Le pas est en effet vite fait de considérer une telle représentation comme un ensemble complet et indépendant.
La visualisation, une porte ouverte, mais pas une fin en soi
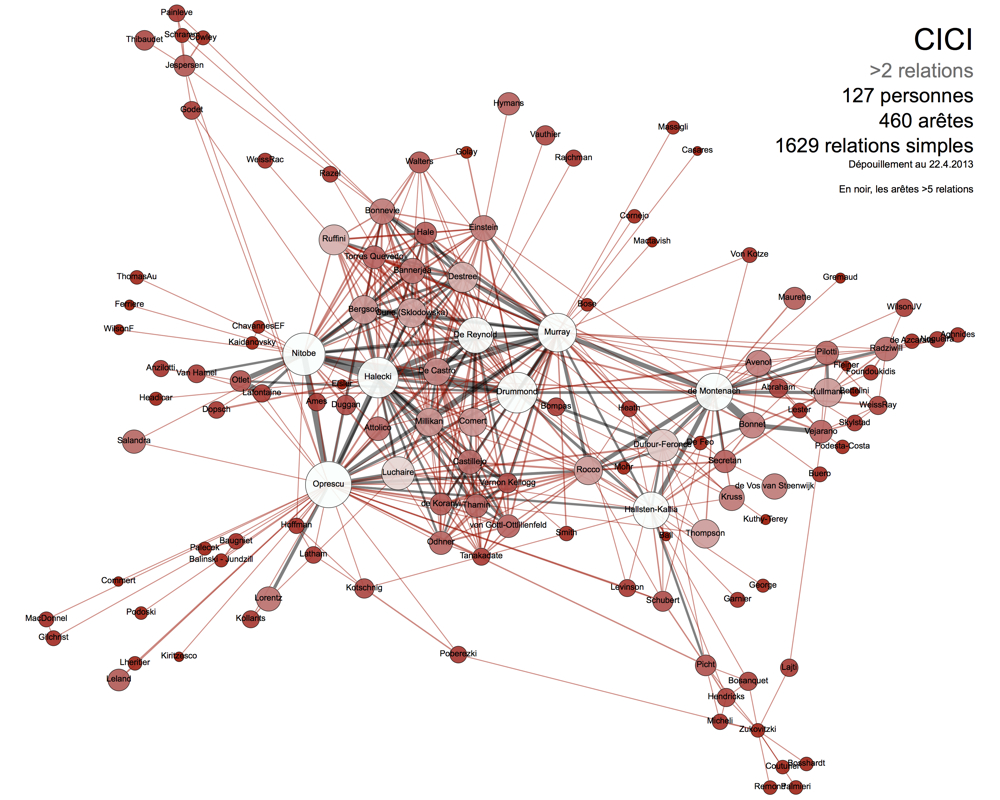
Exemple d’usage du réseau : considérer uniquement les relations entre personnes à partir du moment qu’elles sont répétées (visualisation des arêtes de valeur égale ou supérieure à 2).
Ce réseau archivistique n’est en tant que tel pas un produit mais bien une porte d’entrée qui suscite elle-même ses questions propres et permet d’aborder une problématique en laissant au chercheur l’occasion de construire son objet sur la base de ce panorama, se focalisant ensuite, à partir du réseau global, sur un choix d’éléments mis au jour.
Cette recherche, un “work in progress”
Prenez connaissance de l’étape précédente de dépouillement et visualisation de ce fonds d’archives grâce à ce billet publié il y a un mois et demi :
Analyse de réseau ⎜Cartographier l’activité de la Société des Nations
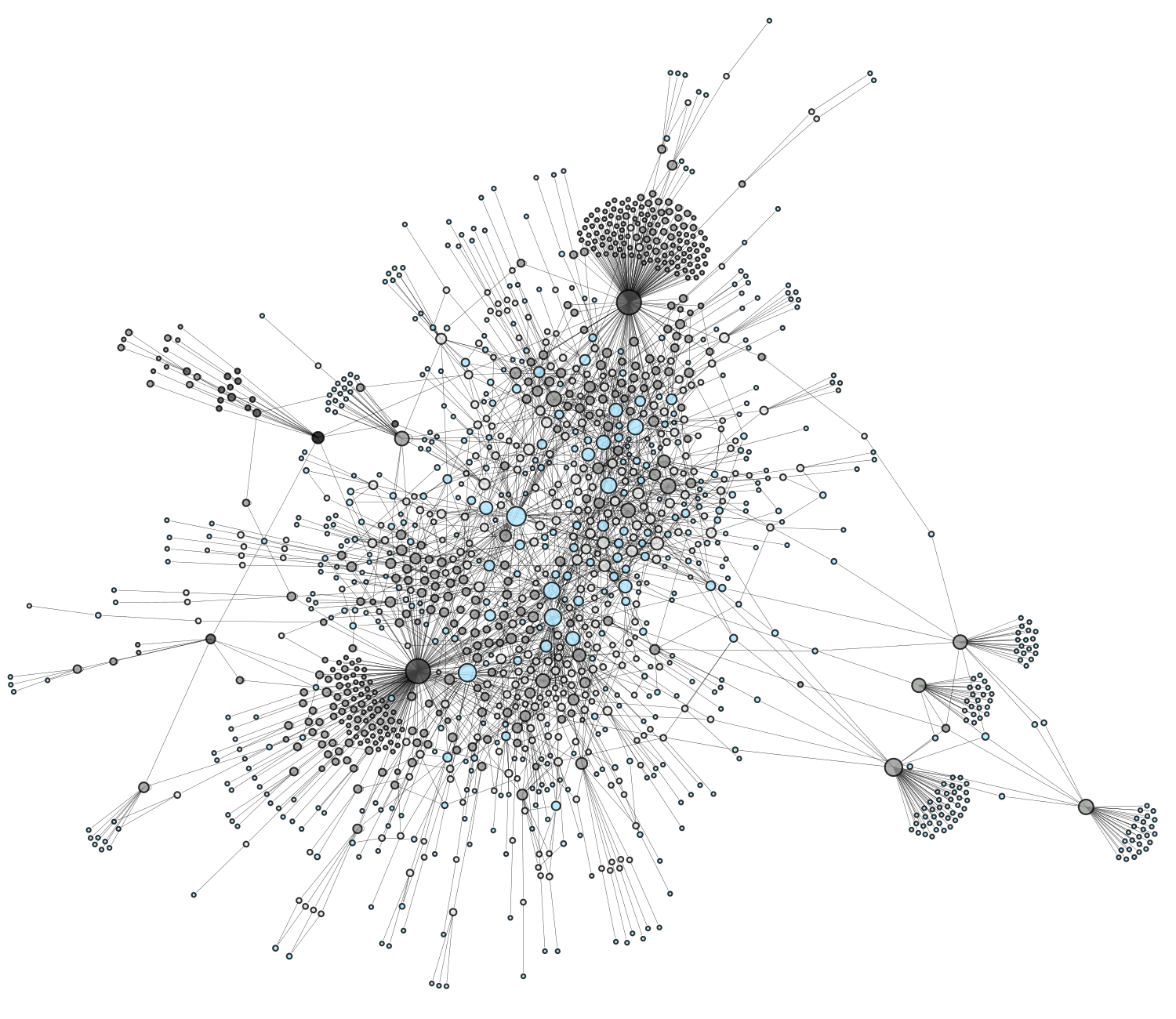 Ce billet en est une suite logique puisque concrétisant le passage d’un réseau sources+personnes (voir exemple ci-contre à gauche, sources en gris et personnes en bleu) à un réseau “interprété” (après projection).
Ce billet en est une suite logique puisque concrétisant le passage d’un réseau sources+personnes (voir exemple ci-contre à gauche, sources en gris et personnes en bleu) à un réseau “interprété” (après projection).
Colloque #dhiha5
Ce billet est une contribution au 5e colloque Digital Humanities de l’Institut historique allemand à Paris (10-11 juin 2013). Elle s’insère en particulier dans la première des quatre thématiques retenues, à savoir “Formes numériques de notre culture scientifique : ce que changent les Digital Humanities”, en ce qu’elle est un exemple de ce que les digital humanities rendent possible : un changement de paradigme de recherche en archivistique par la possibilité d’appréhender un gros corpus de sources dans sa globalité avant de le réduire par des questions de recherche pointues (en opposition avec une méthode plus traditionnelle qui consiste à définir en premier lieu l’objet précis – et les questions qu’on souhaite lui poser – pour le documenter ensuite par les documents d’archive).
Très intéressant billet (comme toujours) mais comment rendre votre méthode diffusable pour une utilisation systématique des historiens à l’endroit des archives s’y prêtant ?
Pareillement, comment obtenir des représentations graphiques de relations d’acteur à acteur à l’ensemble des chercheurs travaillant sur des nuées d’individus ? sans même aller aussi loin de ce qui est présenté ici, où on est déjà dans une dimension qualitative nous permettant de saisir en partie l’intensité de la relation (arrêtes noires). Avez-vous connaissance ou produit par exemple, une application même minimale permettant une représentation graphique des relations d’acteur à acteur ? comme par exemple cette application pour schéma heuristique, très utile quoique rapidement limitée : http://www.text2mindmap.com/
Merci pour votre commentaire.
Cette méthode n’est techniquement pas compliquée puisqu’elle ne nécessite que la mise sur pied d’un tableau à 2 colonnes couplant les 2 éléments que l’on veut lier (ici, personne – personne). La difficulté évidente réside dans le fait que ce tableau ne peut se faire que manuellement à partir du dépouillement des documents d’archives, et est donc à la taille du fonds d’archives.
Au niveau de la représentation graphique, si l’on dispose de ce tableau dans lequel on a répertorié tous les couples de personnes (Henri-Jules; Sébastien-Georges, Jules-Georges,…), la visualisation est rendue très simple par cet outil performant et intuitif qu’est Gephi (un tutoriel ici), encore plus simple (et surtout beaucoup plus puissant) que le text2mindmap que vous évoquez.
Merci pour cette réponse très satisfaisante, je me doutais avoir manqué quelque chose déjà accessible sur ce site… Et pour des éléments que l’on veut lier à plusieurs, Gephi est-il aussi pertinent ? (personne – personne – personne ou personne – groupe – personne)
Pour le dépouillement des documents et le travail fastidieux que cela sous-entend, c’est la peine et le plaisir de l’historien 🙂
Merci pour le commentaire.
Oui, il est évidemment possible de lier des éléments différents mais c’est toujours deux par deux (ce qui n’empêche pas, pour une triade, d’entrer les éléments comme des couples personne1-personne2 ; personne2-personne3 ; personne3-personne1). Dans le cas de graphe composé de plusieurs types de sommets (par exemple groupe-personne), Gephi est tout à fait utilisable, mais il ne s’agit dès lors plus de faire une analyse structurelle puisque les concepts mathématiques de la social network analysis ne s’appliquent en général qu’à des réseaux homogènes. On est donc dans la visualisation de réseau, et plus l’analyse. Un exemple de graphe avec deux types de sommets ici (graphe archives-personnes).
Merci pour ce billet. J’ajouterais que le numérique – ou le digital si l’on s’attache aux incidences de la pratique manuelle des doigts (Walter Benjamin avait écrit un bel article sur l’incidence de la plume et ses évolutions sur les styles d’écriture) – permet d’exploiter de facon neuve les banques de données établies dans des groupes de travail. Le numérique : la fin du thésard solitaire de sciences sociales ?
Oui, le collaboratif, en plus d’être un cheval de bataille des Digital Humanities, est favorisé par le numérique qui ouvre développe cette nouvelle dimension de la recherche : le travail à plusieurs sur un objet de type “compilation” (base de données, base prosopographique, articles encyclopédiques,…) ! Belles perspectives !